I am a postdoctoral researcher at the University of Zagreb specializing in natural language processing. I obtained my PhD (summa cum laude) in 2025 from the Faculty of Electrical Engineering and Computing, University of Zagreb, under the supervision of Jan Šnajder. I completed my bachelor’s degree in 2019 and my master’s degree in 2021 at the same faculty. During my master’s studies, I received the Rector’s Award for scientific research. Since 2021, I have been employed as an assistant at the Faculty of Electrical Engineering and Computing and am a member of TakeLab, where I lead the TakeLab Retriever project. TakeLab Retriever is a platform that scanned and indexed (with topics, named entities and phrases) more than ten million articles published in the last 25 years on Croatian news outlets. During my PhD I co-authored more than ten scientific papers, publishing at leading NLP venues such as ACL and EMNLP. In my last year of PhD, I did a 3-month research visit at WüNLP group in Germany with Professor Goran Glavaš.
Sequence Repetition Enhances Token Embeddings and Improves Sequence Labeling with Decoder-only Language Models
Matija Luka Kukić, Marko Čuljak, David Dukić, Martin Tutek, Jan Šnajder EACL 2026 (Findings) |
paper |
@misc{kukić2026sequencerepetitionenhancestoken,
title={Sequence Repetition Enhances Token Embeddings and Improves Sequence Labeling with Decoder-only Language Models},
author={Matija Luka Kukić and Marko Čuljak and David Dukić and Martin Tutek and Jan Šnajder},
year={2026},
eprint={2601.17585},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2601.17585},
}
Characterizing Linguistic Shifts in Croatian News via Diachronic Word Embeddings David Dukić, Ana Barić, Marko Čuljak, Josip Jukić, Martin Tutek ACL 2025 (SLAVIC NLP Workshop) |
paper |
@inproceedings{dukic-etal-2025-characterizing,
title = "Characterizing Linguistic Shifts in {C}roatian News via Diachronic Word Embeddings",
author = "Duki{\'c}, David and
Bari{\'c}, Ana and
{\v{C}}uljak, Marko and
Juki{\'c}, Josip and
Tutek, Martin",
editor = "Piskorski, Jakub and
P{\v{r}}ib{\'a}{\v{n}}, Pavel and
Nakov, Preslav and
Yangarber, Roman and
Marcinczuk, Michal",
booktitle = "Proceedings of the 10th Workshop on Slavic Natural Language Processing (Slavic NLP 2025)",
month = jul,
year = "2025",
address = "Vienna, Austria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.bsnlp-1.13/",
doi = "10.18653/v1/2025.bsnlp-1.13",
pages = "108--115",
ISBN = "978-1-959429-57-9",
abstract = "Measuring how semantics of words change over time improves our understanding of how cultures and perspectives change. Diachronic word embeddings help us quantify this shift, although previous studies leveraged substantial temporally annotated corpora. In this work, we use a corpus of 9.5 million Croatian news articles spanning the past 25 years and quantify semantic change using skip-gram word embeddings trained on five-year periods. Our analysis finds that word embeddings capture linguistic shifts of terms pertaining to major topics in this timespan (COVID-19, Croatia joining the European Union, technological advancements). We also find evidence that embeddings from post-2020 encode increased positivity in sentiment analysis tasks, contrasting studies reporting a decline in mental health over the same period."
}
Are ELECTRA’s Sentence Embeddings Beyond Repair? The Case of Semantic Textual Similarity
Ivan Rep, David Dukić, Jan Šnajder EMNLP 2024 (Findings) |
paper |
@inproceedings{rep-etal-2024-electras,
title = "Are {ELECTRA}{'}s Sentence Embeddings Beyond Repair? The Case of Semantic Textual Similarity",
author = "Rep, Ivan and
Duki{\'c}, David and
{\v{S}}najder, Jan",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2024",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-emnlp.535/",
doi = "10.18653/v1/2024.findings-emnlp.535",
pages = "9159--9169",
abstract = "While BERT produces high-quality sentence embeddings, its pre-training computational cost is a significant drawback. In contrast, ELECTRA provides a cost-effective pre-training objective and downstream task performance improvements, but worse sentence embeddings. The community tacitly stopped utilizing ELECTRA{'}s sentence embeddings for semantic textual similarity (STS). We notice a significant drop in performance for the ELECTRA discriminator{'}s last layer in comparison to prior layers. We explore this drop and propose a way to repair the embeddings using a novel truncated model fine-tuning (TMFT) method. TMFT improves the Spearman correlation coefficient by over 8 points while increasing parameter efficiency on the STS Benchmark. We extend our analysis to various model sizes, languages, and two other tasks. Further, we discover the surprising efficacy of ELECTRA{'}s generator model, which performs on par with BERT, using significantly fewer parameters and a substantially smaller embedding size. Finally, we observe boosts by combining TMFT with word similarity or domain adaptive pre-training."
}
Looking Right is Sometimes Right: Investigating the Capabilities of Decoder-only LLMs for Sequence Labeling David Dukić, Jan Šnajder ACL 2024 (Findings) |
paper |
@inproceedings{dukic-snajder-2024-looking,
title = "Looking Right is Sometimes Right: Investigating the Capabilities of Decoder-only {LLM}s for Sequence Labeling",
author = "Duki{\'c}, David and
{\v{S}}najder, Jan",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2024",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-acl.843/",
doi = "10.18653/v1/2024.findings-acl.843",
pages = "14168--14181",
abstract = "Pre-trained language models based on masked language modeling (MLM) excel in natural language understanding (NLU) tasks. While fine-tuned MLM-based encoders consistently outperform causal language modeling decoders of comparable size, recent decoder-only large language models (LLMs) perform on par with smaller MLM-based encoders. Although their performance improves with scale, LLMs fall short of achieving state-of-the-art results in information extraction (IE) tasks, many of which are formulated as sequence labeling (SL). We hypothesize that LLMs' poor SL performance stems from causal masking, which prevents the model from attending to tokens on the right of the current token. Yet, how exactly and to what extent LLMs' performance on SL can be improved remains unclear. We explore techniques for improving the SL performance of open LLMs on IE tasks by applying layer-wise removal of the causal mask (CM) during LLM fine-tuning. This approach yields performance gains competitive with state-of-the-art SL models, matching or outperforming the results of CM removal from all blocks. Our findings hold for diverse SL tasks, demonstrating that open LLMs with layer-dependent CM removal outperform strong MLM-based encoders and even instruction-tuned LLMs."
}
Leveraging Open Information Extraction for More Robust Domain Transfer of Event Trigger Detection David Dukić, Kiril Gashteovski, Goran Glavaš, Jan Šnajder EACL 2024 (Findings) |
paper |
@inproceedings{dukic-etal-2024-leveraging,
title = "Leveraging Open Information Extraction for More Robust Domain Transfer of Event Trigger Detection",
author = "Duki{\'c}, David and
Gashteovski, Kiril and
Glava{\v{s}}, Goran and
Snajder, Jan",
editor = "Graham, Yvette and
Purver, Matthew",
booktitle = "Findings of the Association for Computational Linguistics: EACL 2024",
month = mar,
year = "2024",
address = "St. Julian{'}s, Malta",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-eacl.80/",
pages = "1197--1213",
abstract = "Event detection is a crucial information extraction task in many domains, such as Wikipedia or news. The task typically relies on trigger detection (TD) {--} identifying token spans in the text that evoke specific events. While the notion of triggers should ideally be universal across domains, domain transfer for TD from high- to low-resource domains results in significant performance drops. We address the problem of negative transfer in TD by coupling triggers between domains using subject-object relations obtained from a rule-based open information extraction (OIE) system. We demonstrate that OIE relations injected through multi-task training can act as mediators between triggers in different domains, enhancing zero- and few-shot TD domain transfer and reducing performance drops, in particular when transferring from a high-resource source domain (Wikipedia) to a low(er)-resource target domain (news). Additionally, we combine this improved transfer with masked language modeling on the target domain, observing further TD transfer gains. Finally, we demonstrate that the gains are robust to the choice of the OIE system."
}
Target Two Birds With One SToNe: Entity-Level Sentiment and Tone Analysis in Croatian News Headlines
Ana Barić, Laura Majer, David Dukić, Marijana Grbeša-Zenzerović, Jan Šnajder EACL 2023 (SLAVIC NLP Workshop) |
paper |
@inproceedings{baric-etal-2023-target,
title = "Target Two Birds With One {ST}o{N}e: Entity-Level Sentiment and Tone Analysis in {C}roatian News Headlines",
author = "Bari{\'c}, Ana and
Majer, Laura and
Duki{\'c}, David and
Grbe{\v{s}}a-zenzerovi{\'c}, Marijana and
Snajder, Jan",
editor = "Piskorski, Jakub and
Marci{\'n}czuk, Micha{\l} and
Nakov, Preslav and
Ogrodniczuk, Maciej and
Pollak, Senja and
P{\v{r}}ib{\'a}{\v{n}}, Pavel and
Rybak, Piotr and
Steinberger, Josef and
Yangarber, Roman",
booktitle = "Proceedings of the 9th Workshop on Slavic Natural Language Processing 2023 (SlavicNLP 2023)",
month = may,
year = "2023",
address = "Dubrovnik, Croatia",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.bsnlp-1.10/",
doi = "10.18653/v1/2023.bsnlp-1.10",
pages = "78--85",
abstract = "Sentiment analysis is often used to examine how different actors are portrayed in the media, and analysis of news headlines is of particular interest due to their attention-grabbing role. We address the task of entity-level sentiment analysis from Croatian news headlines. We frame the task as targeted sentiment analysis (TSA), explicitly differentiating between sentiment toward a named entity and the overall tone of the headline. We describe SToNe, a new dataset for this task with sentiment and tone labels. We implement several neural benchmark models, utilizing single- and multi-task training, and show that TSA can benefit from tone information. Finally, we gauge the difficulty of this task by leveraging dataset cartography."
}
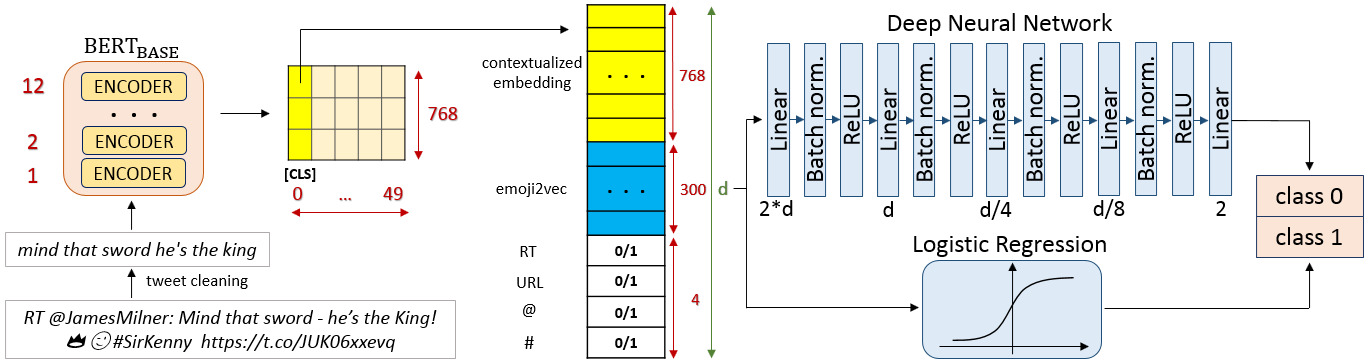
Are You Human? Detecting Bots on Twitter Using BERT David Dukić, Dominik Keča, Dominik Stipić 2020 IEEE 7th International Conference on Data Science and Advanced Analytics |
paper |
@INPROCEEDINGS{9260074,
author={Dukić, David and Keča, Dominik and Stipić, Dominik},
booktitle={2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA)},
title={Are You Human? Detecting Bots on Twitter Using BERT},
year={2020},
volume={},
number={},
pages={631-636},
keywords={Task analysis;Bit error rate;Feature extraction;Social networking (online);Deep learning;Bot (Internet);Logistics;BERT model;bot detection;emoji2vec;gender prediction;latent Dirichlet allocation;shallow vs. deep learning;t-SNE},
doi={10.1109/DSAA49011.2020.00089}}